ooo-Minkun-Bayesian-Modeling-C2
Estimating a distribution?
- Nonparametric Method(KDE): this works well when there is a lot of data without distribution knowledge.
- Parametric Method(MLE): this works better than nonparametric when dataset is smaller and particular distribution is specified.
- Shrinkage Method: this works best for either high dimensional or very small datasets. It combines two weak estimators, one with high variance(Nonparametric) and the other with high bias(parametric), with some coefficient called the shrinkage coefficient(weighting), to produce a much better estimator.
The benefit of using the Nonparametric estimator is that there are no assumptions made about the nature of the underlying distribution. So, this would give us the most general result. In Nonparametric case, the data alone is considered and the distribution is modeled as an "empirical distribution". An empirical distribution is a distribution that has a kernel function at each data pt. This kernel function is defined to be the Dirac delta function, however, due to the difficulty of doing calculus with Dirac delta functions, modern implementations consider the "Gaussian function". If we average out kernel values from all data pt, ...this is smoothing out the empirical distribution, thus we can get our point estimate value? (but the insufficient size of data causes the nonparametric estimators to loose accuracy and become a bad estimator as stated in the "law of large numbers").

Using kernel?
- weighing neighbor points by the distance to our
. The point that are really neighbor to our
- The weight can be computed as the kernel function of "x" (
the x value for the point(y) that we want to predict) andith neighbor point). - In Gaussian kernel, if we take a higher value of sigma, the values would drop slower obviously, so you can weight further points a bit higher...getting closer to Uniform? If sigma is low then the kernel would quickly drop to zero, so each point can get extreme weight. so..sigma is a sort of resistance?
- In Uniform kernel, we equally weigh the points.


> K(center-pt, target-pt) ?
A kernel is used for weighting, determining each kernel value(1/0) for each data point and computing the proportion that is associated with a certain bin. center-pt delivers the bin_ID information while target-pt is what we investigate.
- classification(svm): creating customized feature space
- regression(knn): weighting neighboring points
- otheres: smoothing histogram(kde),...giving customized samples(behaving as the covariance) in the random process
> What is kernel?
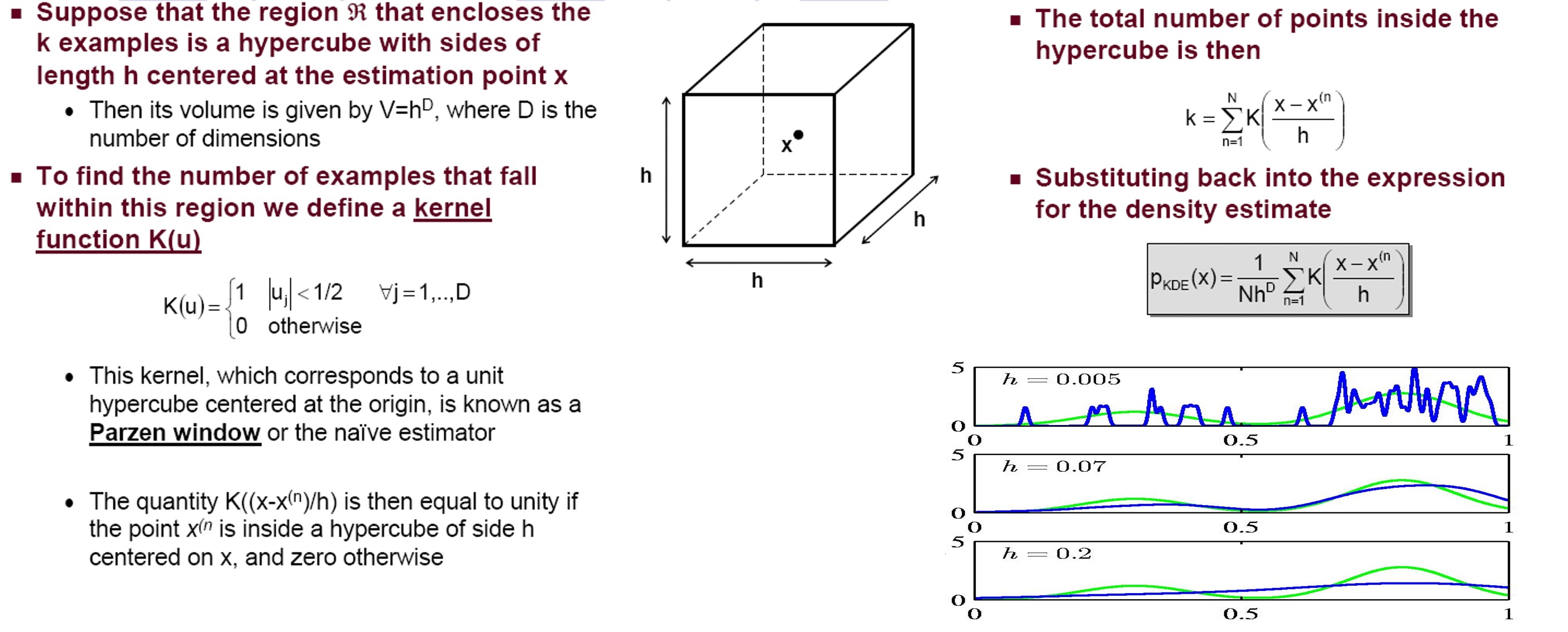
Let's say..when you have a vector X, using a bin (in histogram), you can develop an empirical pdf f(X) without help from parametric assumptions about the underlying distribution. This empirical pdf f(X) uses a kernel function (classification function to accept/reject the data-pt by measuring a certain distance) that explains what's goin on inside the hypercube (bin). The sum of outputs of the kernel function returns total NO.of data-pt falling into the hypercube (bin) which is k.
- (A) Introduction

- (B) KDE and basic kernel
> What is Fourier-Transform?
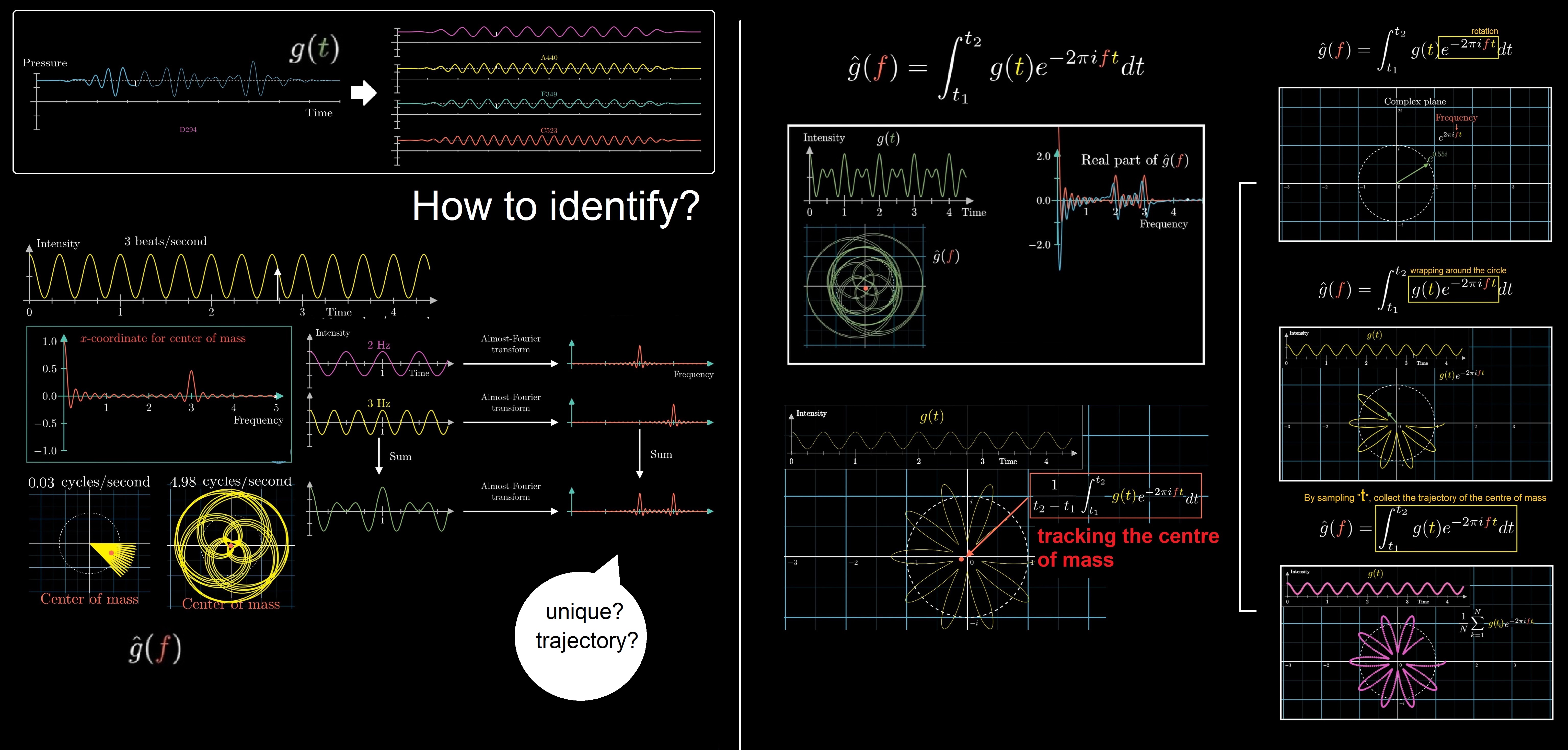
Fourier Transform is a mathematical operation that changes the domain (x-axis) of a signal from time to frequency. In other words, it decomposes a complex wave (a function of time) into the many different waves (made out of sin, cos) that make it up. Of course, i is the imaginary unit, sqrt(-1).
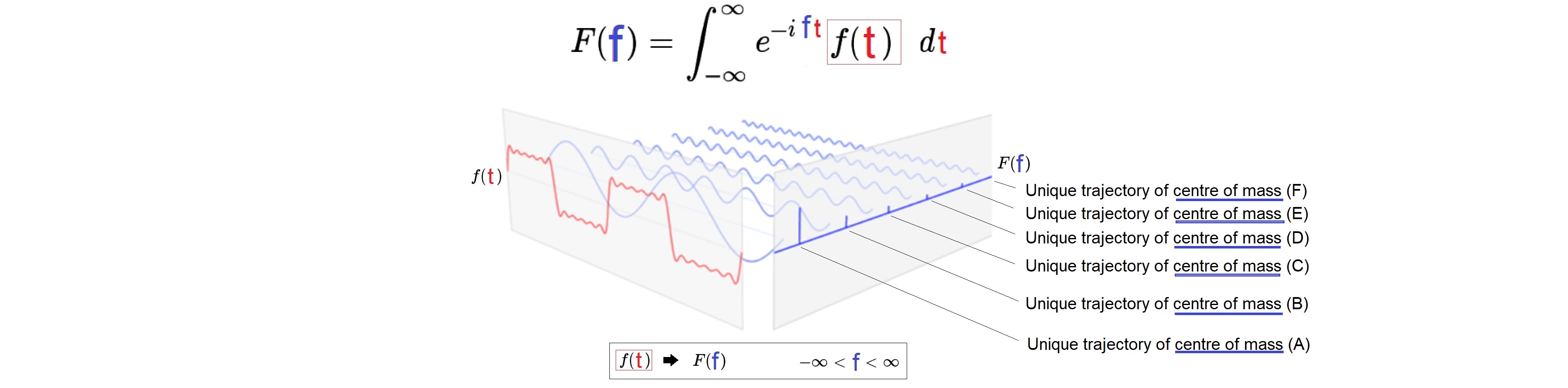
If F(f) is known, the original function f(t) can be obtained by "Inverse Fourier Transform"
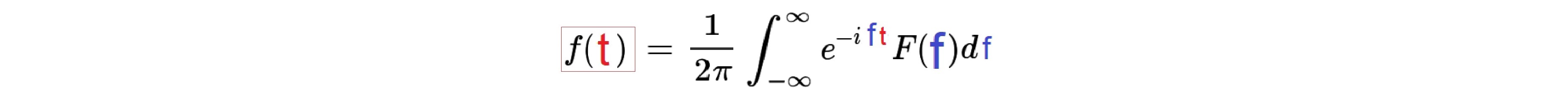
Fourier series is complex-valued functions on a circle. The input will be a point on the circle. The output will be a complex number.
If rotating a function on a circle, we can graph a function on a circle by graphing it on a line segment (the left and right ends have to be connected). The functions are vectors: they can be added, multiplied by a constant. Rotation is Multiplication. Look at what happens when we rotate it by an angle a. The rotation is the same as shifting the argument to the function by a. The thing is... the functions in our buckets have to satisfy the property that rotating them (adding a in the bucket) is the same as multiplying them. And the functions below, where f is any integer, are exactly the functions that do satisfy this property where the coefficients a just tell us how much of each function to take (how much rotate?). This decomposition is called the Fourier Series. Therefore, we can write any function on the circle as a sum of such functions:

> Having a mismeasured predictor? :::: Fourier-Transform + KDE
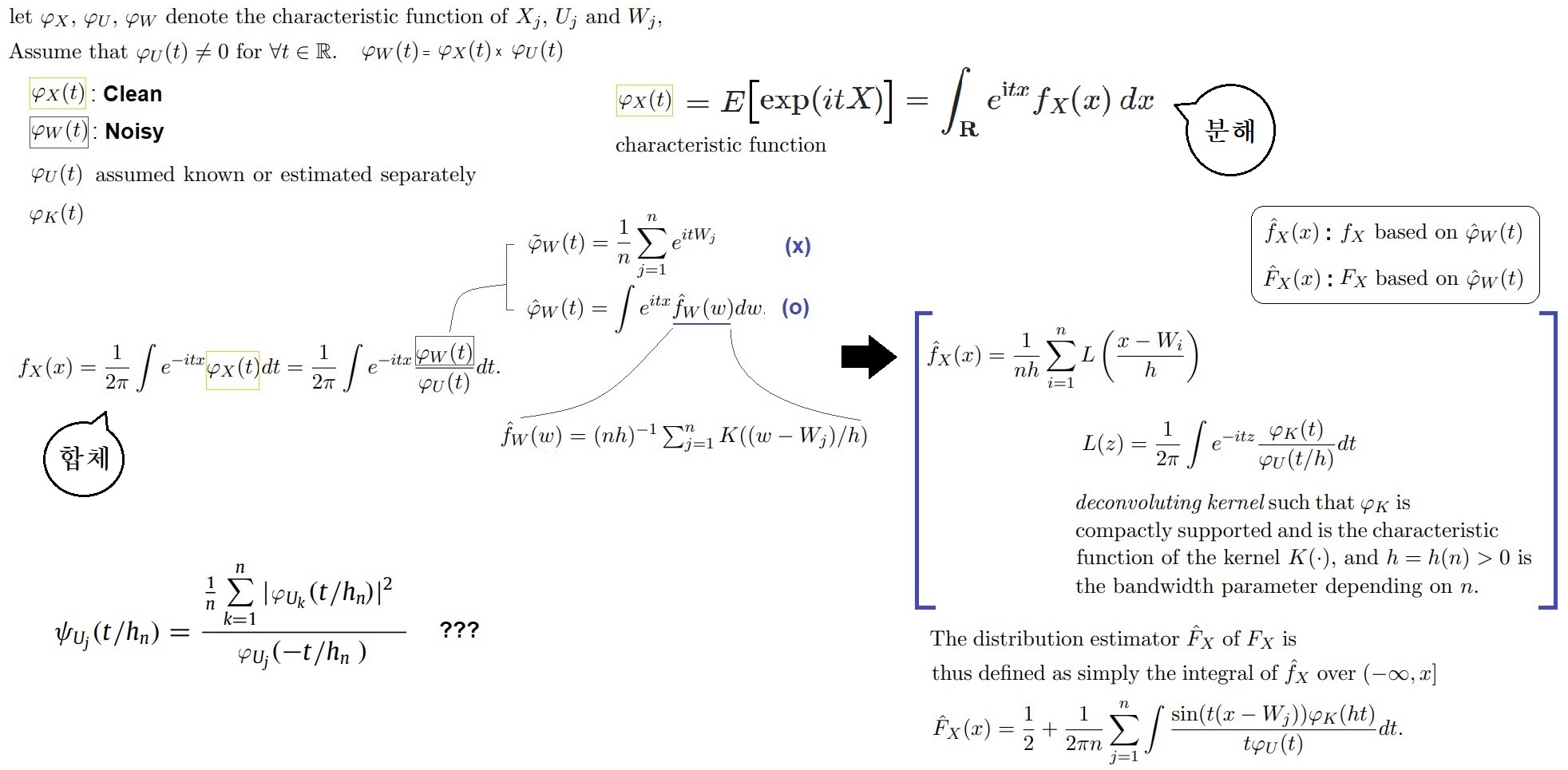
The characteristic function is the Fourier transform of the pdf!!! If a random variable admits a pdf, then its characteristic function is the Fourier transform of the pdf.