krishcy25/K-Means-Clustering-Unsupervised-Learning
This repository focuses on building K-Means Clustering (Unsupervised Learning algorithm) that builds the effective number of cluster grouping/segmentation based on Elbow method.
K-Means-Clustering-Unsupervised-Learning
This repository focuses on building K-Means Clustering (Unsupervised Learning algorithm) that builds the effective number of cluster grouping based on Elbow method.
You can find the code in the repository in the Notebook "K-Means-Clustering (Unsupervised Learning).ipynb". The data file used for this algorithm is included in the repository
"housepricedata.csv"
Introduction
Clustering is an important part of the machine learning pipeline for business or scientific enterprises utilizing data science. As the name suggests, it helps to identify congregations of closely related (by some measure of distance) data points in a blob of data, which, otherwise, would be difficult to make sense of.
“How would we know the actual number of clusters, to begin with?”
This question is critically important because of the fact that the process of clustering is often a precursor to further processing of the individual cluster data and therefore, the amount of computational resource may depend on this measurement.
In the case of a business analytics problem, repercussion could be worse. Clustering is often done for such analytics with the goal of market segmentation. It is, therefore, easily conceivable that, depending on the number of clusters, appropriate marketing personnel will be allocated to the problem. Consequently, a wrong assessment of the number of clusters can lead to sub-optimum allocation of precious resources.
The elbow method
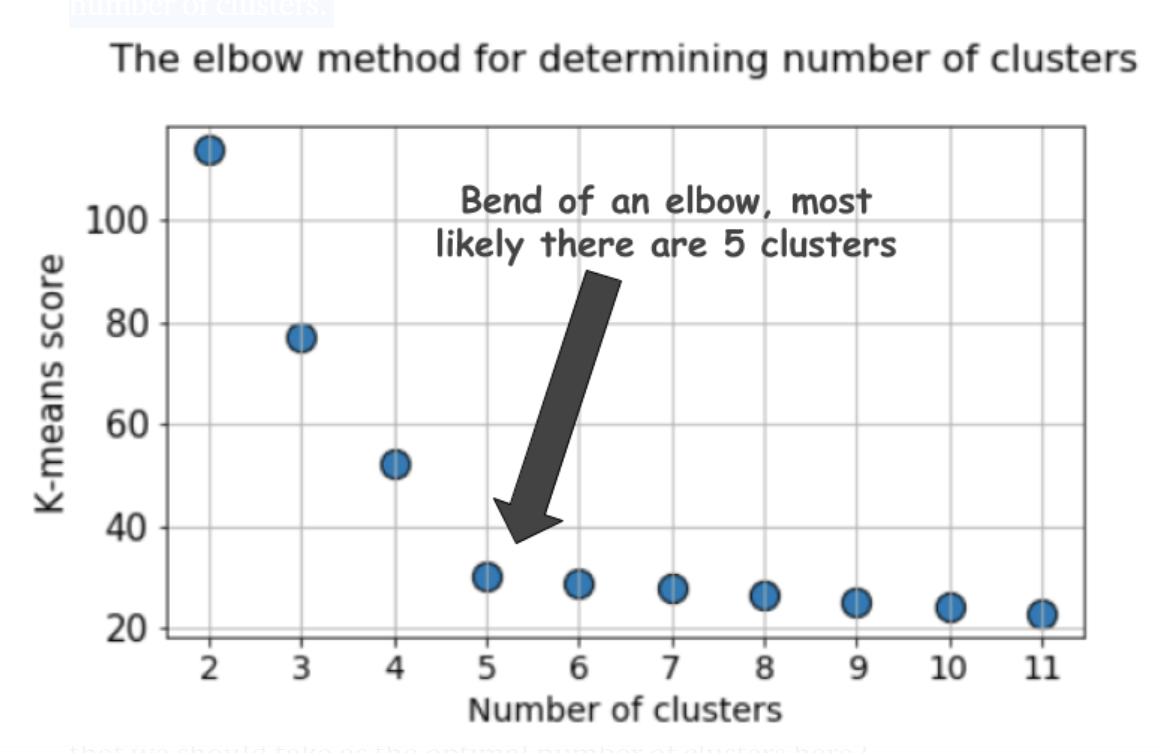
For the k-means clustering method, the most common approach for answering this question is the so-called elbow method. It involves running the algorithm multiple times over a loop, with an increasing number of cluster choice and then plotting a clustering score as a function of the number of clusters.
What is the score or metric which is being plotted for the elbow method? Why is it called the ‘elbow’ method?
A typical plot looks like following