hecforga/scar-project
Memoria del proyecto de SCAR
En esta memoria se recogen los detalles sobre la implementación de los 3 tipos de recomendación presentes en este proyecto de la asignatura "Sistemas Complejos Adaptativos y Recomendación" de la UPV, realizado por el alumno Héctor Fornes Gabaldón.
El resultado final puede verse en la siguiente DEMO (para hacer login, basta con introducir el identificador de un usuario, p. ej. el "1").
Tecnologías utilizadas
Antes de entrar en los detalles de implementación, se considera oportuno comentar la arquitectura y las diferentes tecnologías que han sido utilizadas para la realización del proyecto.
En primer lugar, cabe destacar que el lenguaje de programación escogido, debido al hecho de ser una aplicación web, es TypeScript. Más concretamente, se ha utilizado el framework Next.js, por ofrecer una forma sencilla de integrar el frontend y el backend en una misma base de código. Una peculiaridad del backend que ofrece, es que se trata de funciones serverless, las cuales, y en el contexto de la primera parte de la asignatura, podrían considerarse como agentes cuyo tiempo de vida se limita a la ejecución de una tarea corta y específica.
En cuanto a la base de datos, se ha utilizado una PostgreSQL alojada en Azure, y para facilitar el lanzamiento de consultas se ha utilizado el ORM Prisma. Esta librería ofrece una funcionalidad que está relacionada con la primera parte de la asignatura, pues permite definir la estructura de la base de datos en un esquema que contiene las diferentes entidades con sus propiedades, a la vez que las relaciones entre ellas. Este esquema podría considerarse como una especie de ontología, y además ofrece otra ventaja, y es que genera todos los tipos de TypeScript necesarios para luego poder usarlos a lo largo de la aplicación. A continuación, puede verse el esquema:
model User {
id Int @id @default(autoincrement())
age Int
gender String
occupation String
ratings Rating[]
preferences Preference[]
leftSideNeighborhoods Neighborhood[] @relation("leftSideNeighborhoods")
rightSideNeighborhoods Neighborhood[] @relation("rightSideNeighborhoods")
}
model Genre {
id Int @id @default(autoincrement())
name String
items GenresOnItems[]
preferences Preference[]
}
model Item {
id Int @id @default(autoincrement())
title String
genres GenresOnItems[]
ratings Rating[]
}
model GenresOnItems {
item Item @relation(fields: [itemId], references: [id])
itemId Int // relation scalar field (used in the `@relation` attribute above)
genre Genre @relation(fields: [genreId], references: [id])
genreId Int // relation scalar field (used in the `@relation` attribute above)
@@id([itemId, genreId])
}
model Rating {
id Int @id @default(autoincrement())
rating Int
user User @relation(fields: [userId], references: [id])
userId Int
item Item @relation(fields: [itemId], references: [id])
itemId Int
}
model Preference {
id Int @id @default(autoincrement())
value Int
user User @relation(fields: [userId], references: [id])
userId Int
genre Genre @relation(fields: [genreId], references: [id])
genreId Int
}
model Neighborhood {
id Int @id @default(autoincrement())
distance Float
leftUser User @relation(fields: [leftUserId], references: [id], name: "leftSideNeighborhoods")
leftUserId Int
rightUser User @relation(fields: [rightUserId], references: [id], name: "rightSideNeighborhoods")
rightUserId Int
}Este esquema, además, se ve vitaminado en tiempo de ejecución mediante consultas al API de The Open Movie Database, de donde se obtienen los pósters de las diferentes películas.
Por último, la demo está alojada en un servidor Vercel, el cual ofrece alojamiento gratuito para aplicaciones pequeñas y con varias limitaciones que provocan que en ocasiones las funciones serverless den errores de timeout. Este servidor se ha conectado con los workflows de GitHub, de manera que cada vez que se realiza un push al repositorio, y también de forma automática una vez al día, se realiza un deploy en el que se ejecutan una serie de cálculos que agilizan la carga de las recomendaciones. De este tema se hablará en posteriores secciones.
Inicio de sesión y registro de nuevos usuarios
Uno de los objetivos de esta aplicación es poder observar cómo las recomendaciones cambian entre usuarios con diferentes preferencias. Para conseguirlo, se ha cargado, previa conversión al formato esperado por la base de datos mediante el seeder, la información de los ficheros de texto proporcionados en PoliformaT. Estos ficheros contienen:
- 943 usuarios
- 1682 películas
- 19 géneros
- 80000 valoraciones de usuarios a diferentes películas, puntuando del 1 al 5
La aplicación cuenta, pues, con una pantalla para iniciar sesión mediante el identificador del usuario, y otra pantalla para crear un nuevo usuario. En la pantalla de registro se debe introducir la información demográfica. De momento, no se permite la introducción o modificación de valoraciones, ni para usuarios ya existentes ni para los nuevos.
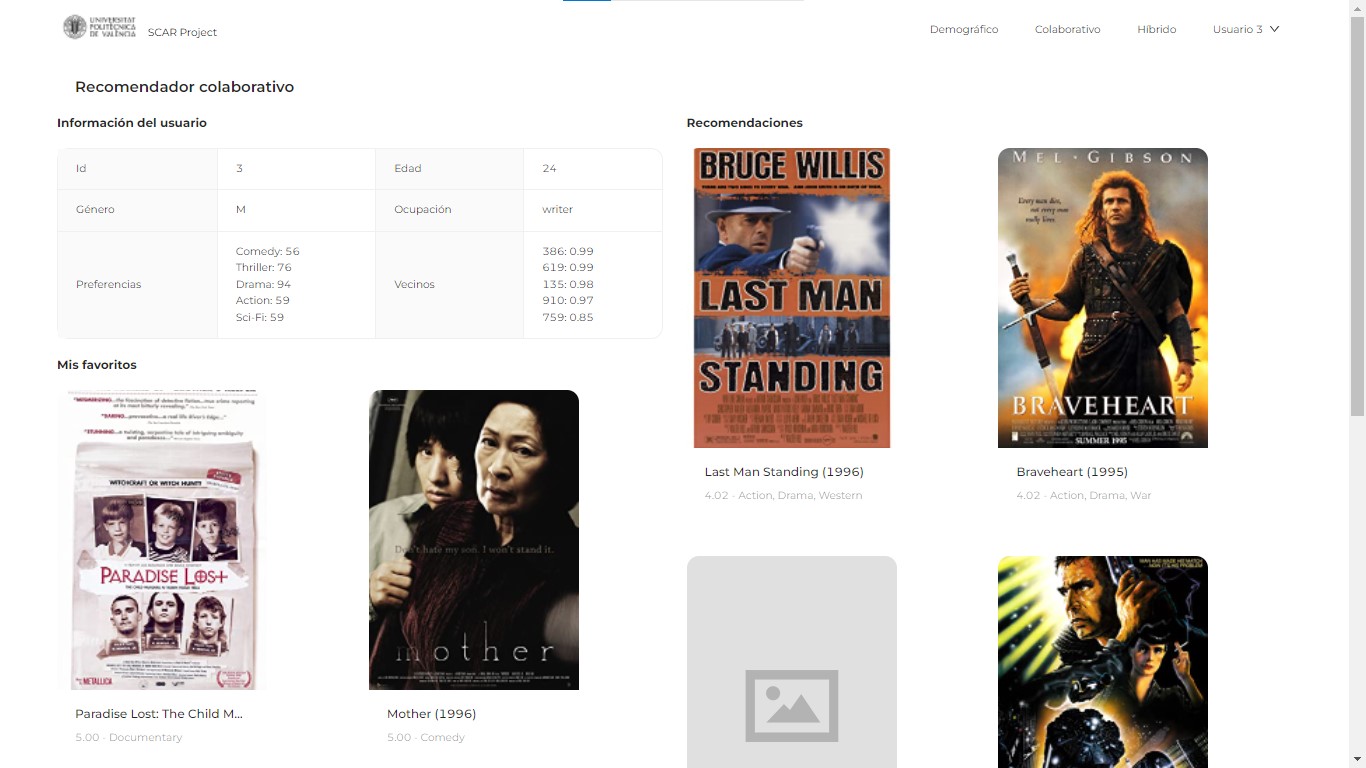
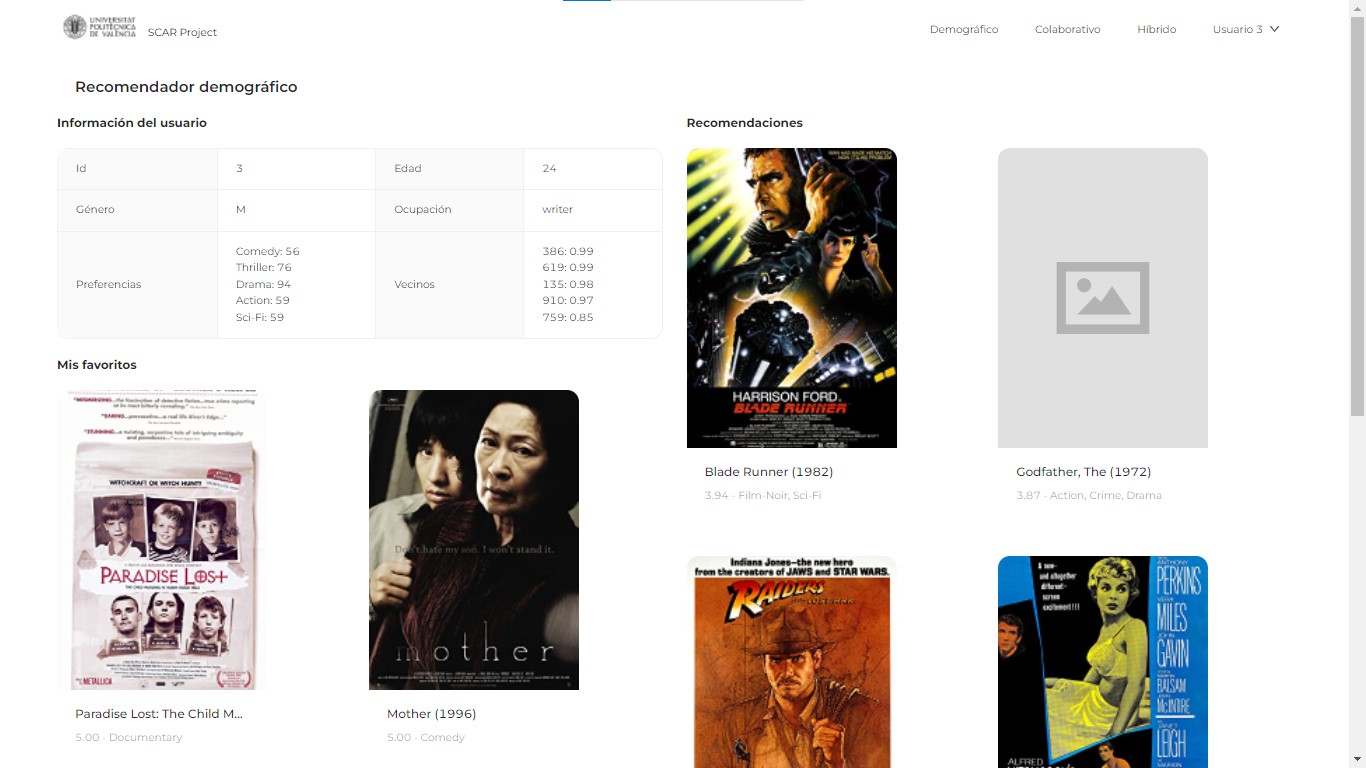
Recomendador demográfico
Para la implementación del recomendador demográfico, se ha optado por agrupar a los usuarios que comparten género, profesión y que se encuentran en la misma decena (de 20 a 29, de 30 a 39, etc.). En cuanto a la fórmula para calcular los ratios, se ha elegido adaptar el llamado weighted rating y que es utilizado por IMDb.

La implementación de esta fórmula en TypeScript puede verse en el siguiente fragmento de código:
export const computeRecommendedItems = async (
user: User,
ratings: Rating[],
users: User[],
items: MyItem[]
): Promise<RecommendedItem[]> => {
let recommendedItemsIds: number[] = [];
const ratingsWithGenreAsString: MyRatingWithGenreAsString[] =
convertGenresToString(
ratings.map((rating) => {
const ratingUser = users.find((u) => u.id === rating.userId);
const ratingItem = items.find((i) => i.id === rating.itemId);
return {
...rating,
user: ratingUser,
item: ratingItem!,
};
})
);
const minAge = Math.trunc(user.age / 10) * 10;
const maxAge = minAge + 9;
const filteredRatings = ratingsWithGenreAsString.filter((rating) => {
const ratingUser = users.find((u) => u.id === rating.userId);
return (
ratingUser &&
rating.userId !== user.id &&
ratingUser.age >= minAge &&
ratingUser.age <= maxAge &&
ratingUser.gender === user.gender &&
ratingUser.occupation === user.occupation
);
});
let ratingsDf = new DataFrame(filteredRatings);
if (filteredRatings.length === 0) {
recommendedItemsIds = (
await new DataFrame(ratingsWithGenreAsString).sample(6)
)['itemId'].values as number[];
return getRecommendedItemsFormIds(
ratingsWithGenreAsString,
recommendedItemsIds
);
}
ratingsDf = ratingsDf
.groupby(['itemId'])
.agg({ rating: ['mean', 'count'] }) as DataFrame;
const c = ratingsDf['rating_mean'].mean();
const m = computeQuantile(ratingsDf, 'rating_count', 0.9);
const computeWeightedRating = (row: number[]): number => {
const v = row[2];
const r = row[1];
return (v / (v + m)) * r + (m / (m + v)) * c;
};
ratingsDf.addColumn(
'score',
ratingsDf.apply(computeWeightedRating).values as number[],
{ inplace: true }
);
ratingsDf = ratingsDf
.sortValues('score', { ascending: false })
.head(6) as DataFrame;
recommendedItemsIds = ratingsDf['itemId'].values as number[];
for (let itemId of recommendedItemsIds) {
const recommendedItem = ratingsWithGenreAsString.find(
(rating) => rating.itemId === itemId
);
if (recommendedItem) {
recommendedItem.rating = ratingsDf.loc({
rows: ratingsDf['itemId'].eq(recommendedItem.itemId),
})['score'].values[0];
}
}
return getRecommendedItemsFormIds(
ratingsWithGenreAsString,
recommendedItemsIds
);
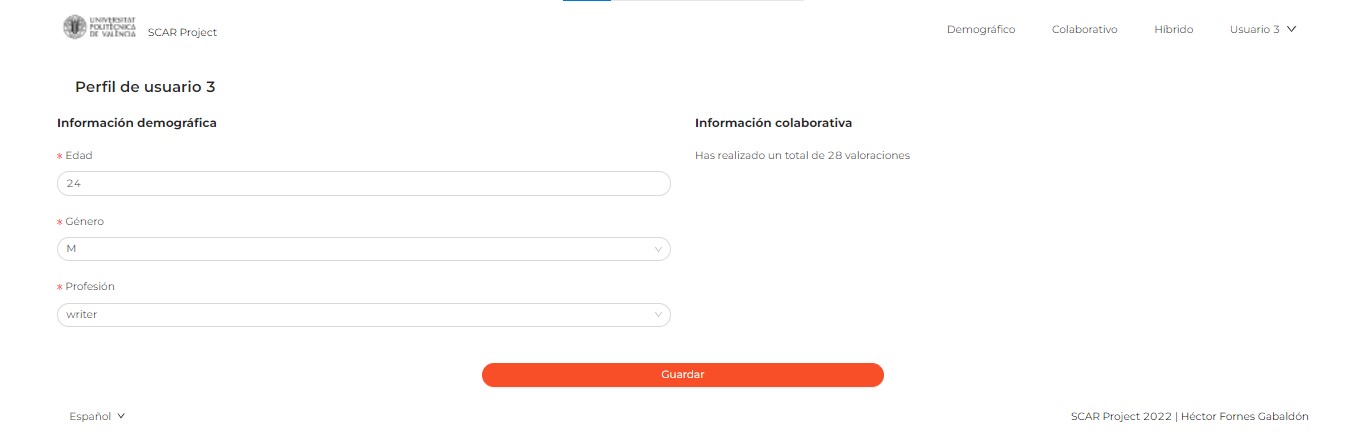
};Además, existe una pantalla de perfil en la que se permite modificar la información demográfica. Puede comprobarse cómo las recomendaciones cambiar al modificar dicha información. A continuación, se incluyen pantallazos de las pantallas relevantes para esta sección:
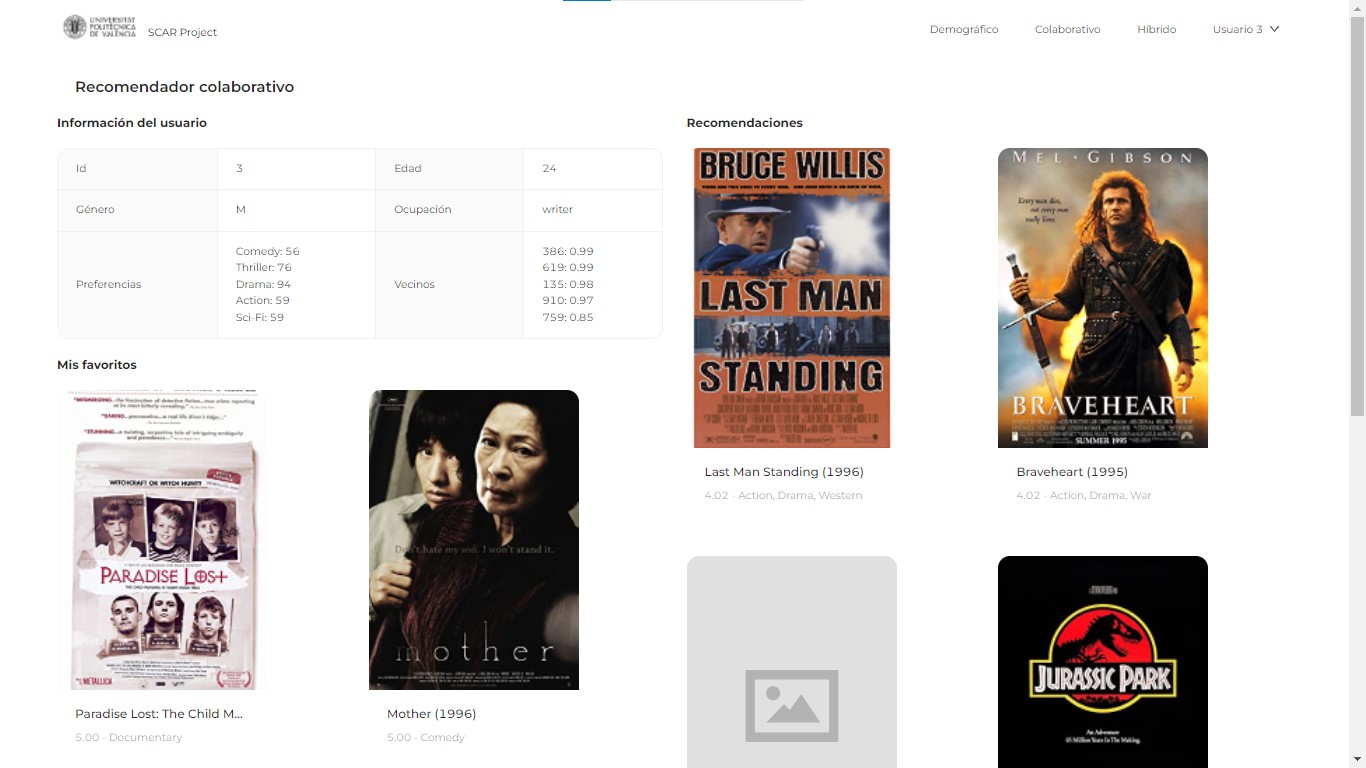
Recomendador colaborativo
Lo más destacable del recomendador colaborativo, es que, al tratarse de un cálculo más exigente en cuanto a recursos, se ha dividido en 2 fases:
- Una que se realiza de forma automática una vez al día y que consiste en el cálculo de preferencias y vecinos.
- Y otra que se realiza en tiempo de ejecución, en el momento en el que un usuario solicita visualizar sus recomendaciones colaborativas.
Cálculo de preferencias y vecinos
Las preferencias se han hecho a nivel de género, eligiendo los 5 más votados por cada usuario. Al más votado se le ha dado un rating de 100, y al quinto más votado un rating de 60, entiendo el primer valor como un sobresaliente y el segundo como un bien. Los géneros del segundo al cuarto obtienen una puntuación ponderada entre estas 2 cifras. Además, para dotar de variabilidad al sistema, todos estos ratings se ven sometidos a un proceso de randomización al verse multiplicados por un número aleatorio entre 0,9 y 1.
En cuanto a los vecinos, y como se proponía en las diapositivas de la asignatura, se ha utilizado la distancia de Pearson para obtener los 5 vecinos más cercanos a cada usuario.
Toda esta información se elimina y se vuelve a regenerar una vez al día de forma automática.
Cálculo de recomendaciones
Para obtener las recomendaciones colaborativas, se ha tenido en cuenta la distancia con los 5 primeros vecinos. Esta distancia se ha multiplicado por el rating de cada película valorada por cada vecino para calcular el rating final. Como peculiaridad, se ha querido recompensar a aquellas películas que coincidían en más de un vecino, multiplicando el resto de películas por 0,95. El código encargado de realizar estos cálculos puede verse a continuación:
export const computeRecommendedItems = async (
myRatings: MyRatingWithGenreAsString[],
neighbours: MyNeighborhood[],
ratings: Rating[],
users: User[],
items: MyItem[]
): Promise<RecommendedItem[]> => {
const neighboursRatings = neighbours
.map((neighbour) =>
neighbour.rightUser.ratings.map((rating) => ({
...rating,
distance: neighbour.distance,
}))
)
.reduce(
(previousValue, currentValue) => [
...previousValue,
...currentValue.map((rating) => ({
...rating,
rating: rating.rating * rating.distance,
})),
],
[]
)
.filter(
(neighbourRating) =>
!myRatings
.map((rating) => rating.itemId)
.includes(neighbourRating.itemId)
);
const itemsWithRating: (Item & {
genres: string[];
rating: number;
times: number;
})[] = [];
for (let neighbourRating of neighboursRatings) {
const itemWithRating = itemsWithRating.find(
(item) => item.id === neighbourRating.itemId
);
if (itemWithRating) {
itemWithRating.rating =
(neighbourRating.rating + itemWithRating.rating) / 1.9;
itemWithRating.times += 1;
} else {
itemsWithRating.push({
...neighbourRating.item,
rating: neighbourRating.rating,
times: 1,
});
}
}
if (itemsWithRating.length === 0) {
const ratingsWithGenreAsString: MyRatingWithGenreAsString[] =
convertGenresToString(
ratings.map((rating) => {
const ratingUser = users.find((u) => u.id === rating.userId);
const ratingItem = items.find((i) => i.id === rating.itemId);
return {
...rating,
user: ratingUser,
item: ratingItem!,
};
})
);
const recommendedItemsIds = (
await new DataFrame(ratingsWithGenreAsString).sample(6)
)['itemId'].values as number[];
return getRecommendedItemsFormIds(
ratingsWithGenreAsString,
recommendedItemsIds
);
}
const maxTimes = [...itemsWithRating].sort((a, b) => b.times - a.times)[0]
.times;
for (let itemWithRating of itemsWithRating) {
itemWithRating.rating = itemWithRating.rating * 0.95 ** maxTimes;
}
return [...itemsWithRating].sort((a, b) => b.rating - a.rating).slice(0, 6);
};En este caso, la posibilidad de modificar y/o añadir valoraciones ha quedado pendiente para futuros trabajos. Sin embargo, puede comprobarse utilizando la demo cómo cada usuario obtiene unas valoraciones diferentes, así como la distancia con sus primeros 5 vecinos, que era el objetivo principal de este trabajo. A continuación, se incluye un pantallazo del recomendador colaborativo:
Recomendador híbrido
Por último, queda por comentar el recomendador híbrido. Para su implementación, se ha optado por un enfoque sencillo, que consiste en obtener 6 recomendaciones del demográfico y 6 del colaborativo, para después coger las 3 mejores de cada unode ellos. Si alguna de las películas coincide, se va rellenando la lista de resultados con las que han quedado en la recámara hasta obtener 6 ítems diferentes. El código encargado de esta funcionalidad es el siguiente:
export const getServerSideProps: GetServerSideProps<ServerSideProps> = async ({
req,
res,
}) => {
const session = await getSession({ req });
let recommendedItems: RecommendedItem[] = [];
let preferences: MyPreference[] = [];
let neighbours: MyNeighborhood[] = [];
let myRatings: MyRatingWithGenreAsString[] = [];
if (session) {
const ratings = await getRatings();
const users = await getUsers();
const items = await getItems();
myRatings = convertGenresToString(await getMyRatings(session.user.id));
preferences = await getPreferences(session.user.id);
neighbours = (await getNeighborhood(session.user.id)).map((neighbour) => ({
...neighbour,
rightUser: {
...neighbour.rightUser,
ratings: convertGenresToString(neighbour.rightUser.ratings),
},
}));
const collaborativeRecommendedItems =
await collaborativeUtils.computeRecommendedItems(
myRatings,
neighbours,
ratings,
users,
items
);
const demographicRecommendedItems =
await demographicUtils.computeRecommendedItems(
session.user,
ratings,
users,
items
);
let collaborativeCount = 0;
let demographicCount = 0;
while (recommendedItems.length < 6) {
if (collaborativeCount <= demographicCount) {
const collaborativeItem =
collaborativeRecommendedItems[collaborativeCount];
if (!recommendedItems.find((i) => i.id === collaborativeItem.id)) {
recommendedItems.push(collaborativeItem);
}
collaborativeCount += 1;
} else {
const demographicItem = demographicRecommendedItems[demographicCount];
if (!recommendedItems.find((i) => i.id === demographicItem.id)) {
recommendedItems.push(demographicItem);
}
demographicCount += 1;
}
}
console.log(collaborativeCount);
console.log(demographicCount);
recommendedItems = [...recommendedItems].sort(
(a, b) => b.rating - a.rating
);
myRatings = myRatings.filter((r) => r.rating === 5).slice(0, 4);
} else {
res.statusCode = 403;
}
return {
props: { recommendedItems, preferences, neighbours, ratings: myRatings },
};
};A continuación, y para concluir con esta memoria, se muestra una captura de la pantalla del recomendador híbrido: