Shreek195/bank-customer-churn-prediction-hpo
End-to-end machine learning pipeline to predict bank customer churn using Decision Tree and Random Forest, with feature engineering, evaluation, and hyperparameter tuning.
Banking Customer Churn Prediction
Predicting customer churn using machine learning to enable proactive retention strategies and reduce revenue loss for banking institutions.
Business Problem
Customer churn is a critical challenge in the banking sector, with acquiring new customers costing 5-25 times more than retaining existing ones. This project addresses the need for early identification of at-risk customers, enabling banks to:
- Reduce Revenue Loss: Predict churners before they leave, allowing timely intervention
- Optimize Marketing Spend: Target retention campaigns to high-risk customers
- Improve Customer Lifetime Value: Implement personalized retention strategies
- Resource Allocation: Focus relationship managers on accounts most likely to churn
Key Findings
Model Performance
| Model | Training Accuracy | Testing Accuracy | F1 Score | Precision | Recall |
|---|---|---|---|---|---|
| Decision Tree | 89.99% | 84.65% | 0.85 | 0.85 | 0.85 |
| Random Forest | 90.47% | 85.00% | 0.85 | 0.85 | 0.85 |
Random Forest demonstrated superior generalization with balanced performance across all metrics.
Critical Business Insights
Customer Churn Distribution
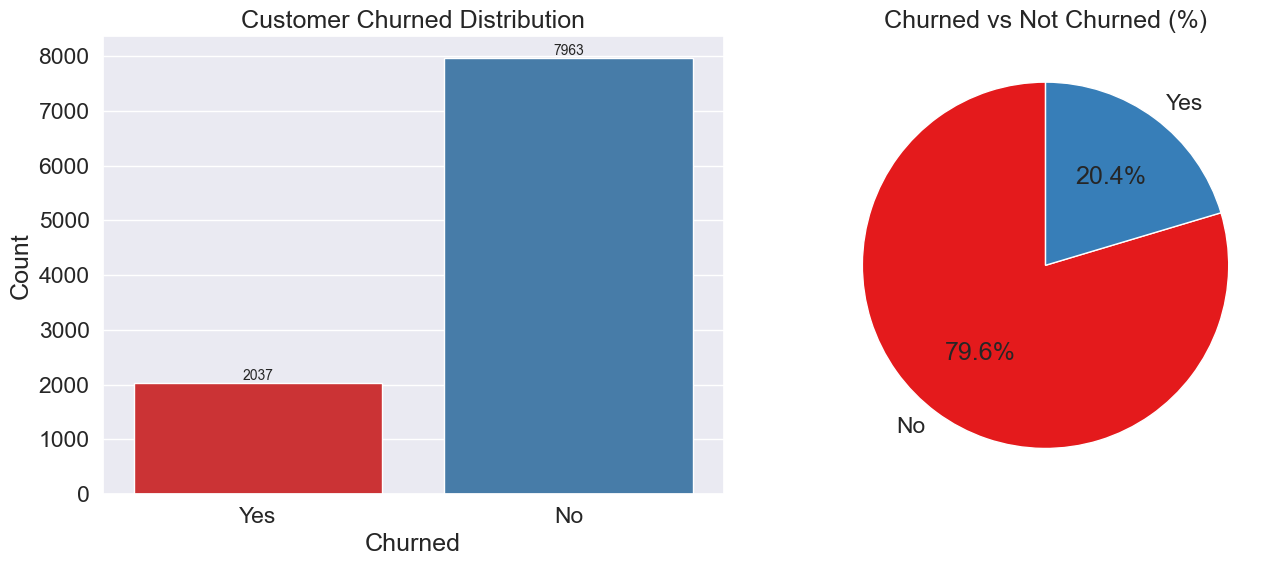
79.6% customers retained vs 20.4% churned — SMOTE applied to balance dataset.
Geography & Product Impact on Churn
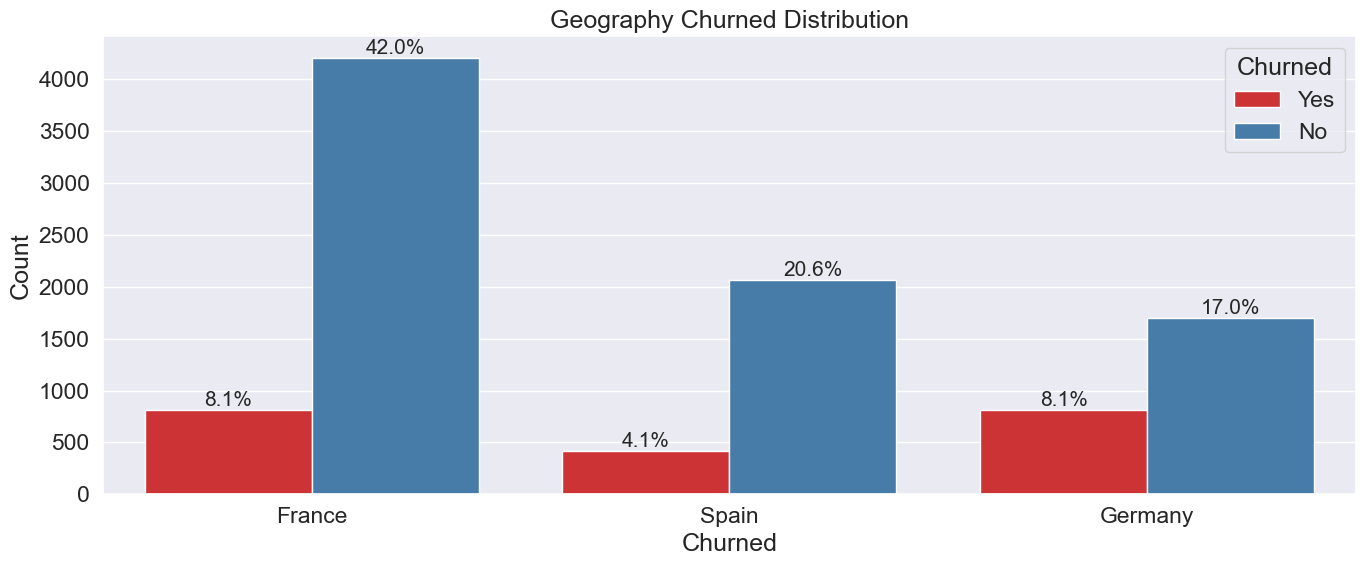
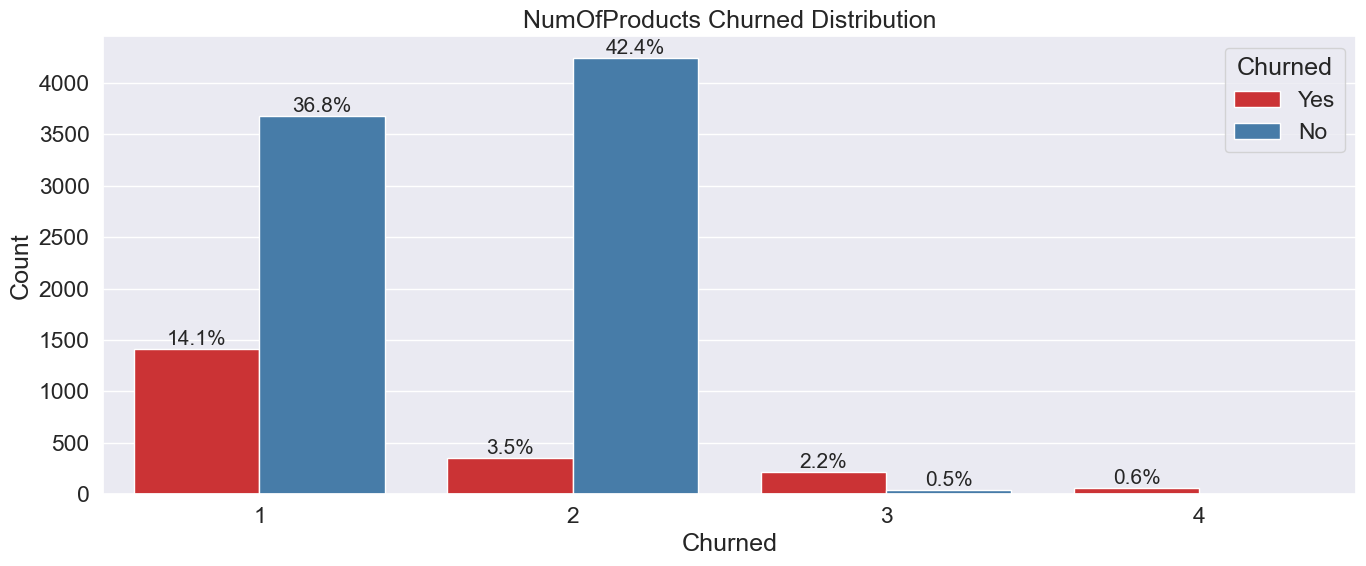
Germany shows 2× higher churn rate; two-product customers are most loyal.
Product Strategy: Customers with exactly 2 products have the lowest churn rate. Single-product customers show significantly higher attrition.
Feature Importance Analysis
Feature Importance — Top Predictors of Churn
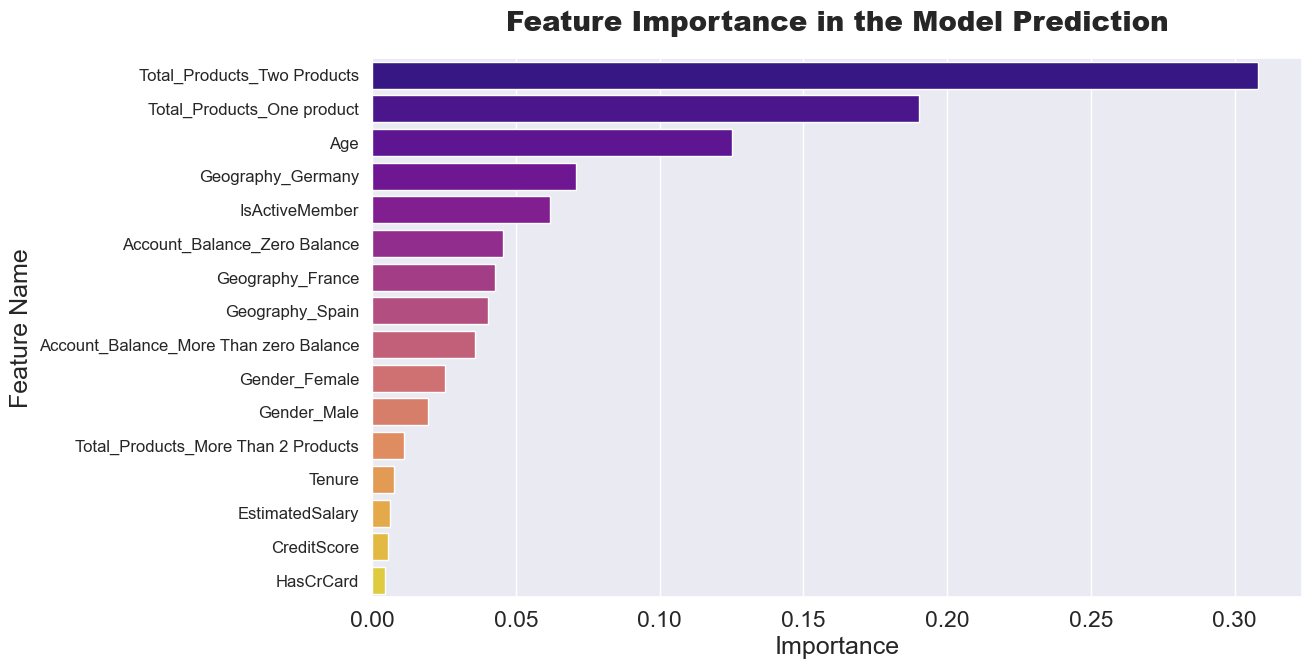
Age, Account Balance, and Geography dominate churn prediction.
Top Predictors:
- Age (log-transformed): Older customers show higher churn propensity
- Account Balance: Zero-balance accounts are strong churn indicators
- Geography: Regional factors significantly impact retention
- Number of Products: Product engagement inversely correlates with churn
Methodology
Data Overview
- Dataset: 10,000 customer records from banking institution
- Features: 14 variables including demographics, account details, and banking behavior
- Target: Binary classification (Churned: Yes/No)
- No Data Leakage: Zero duplicate records, no missing values
Preprocessing Pipeline
-
Feature Engineering
- Categorized
NumOfProducts: Single, Two, More than 2 - Binary transformation of
Balance: Zero vs Non-zero - Removed irrelevant identifiers (RowNumber, CustomerId, Surname)
- Categorized
-
Data Transformation
- Log-normal transformation on
Ageto correct right skewness - One-Hot Encoding for categorical variables
- Label encoding for target variable
- Log-normal transformation on
-
Class Balancing
- Applied SMOTE (Synthetic Minority Over-sampling Technique)
- Balanced training set: 6,356 samples per class
Model Development
Decision Tree
- GridSearchCV hyperparameter tuning (5-fold CV)
- Optimized parameters: entropy criterion, max_depth=9, min_samples_leaf=2
Random Forest (Selected Model)
- Ensemble of 50 decision trees
- Parameters: max_depth=8, min_samples_leaf=3, class_weight='balanced'
- Superior generalization and robustness to overfitting
Model Evaluation
Confusion Matrix & ROC-AUC Curve
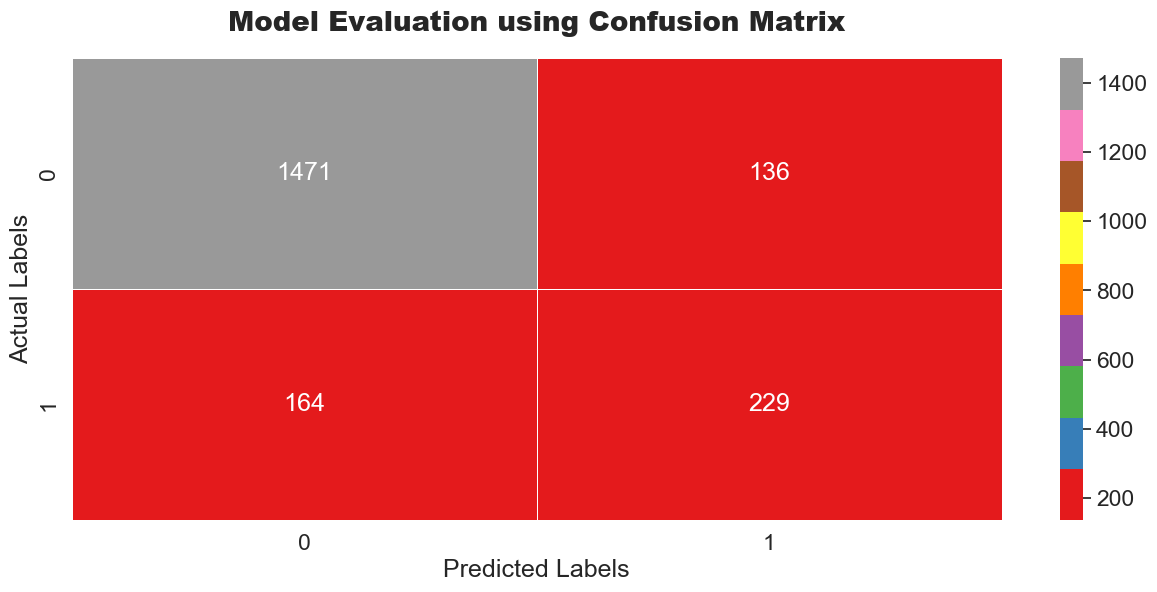
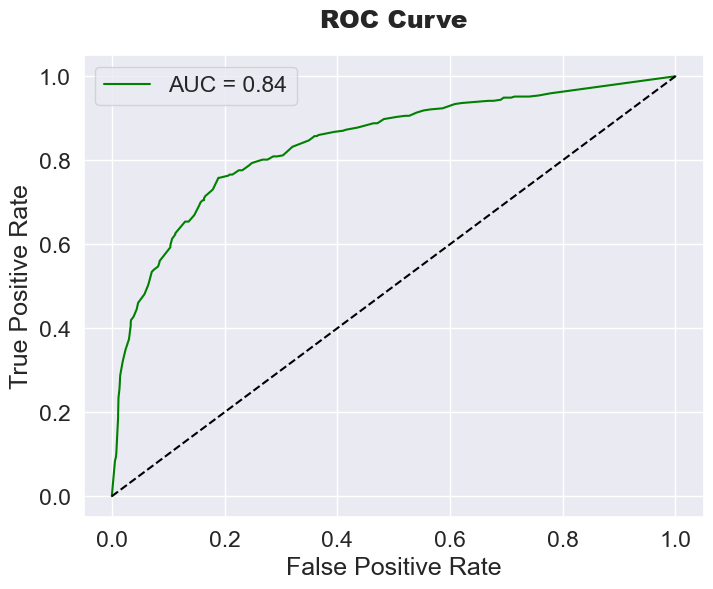
Strong separation with ROC-AUC = 0.86 indicating robust model discrimination.
Confusion Matrix Analysis:
- True Negatives: 1,471 (correctly identified non-churners)
- False Positives: 136 (acceptable over-prediction for proactive intervention)
- False Negatives: 164 (critical misses requiring model refinement)
- True Positives: 229 (successfully identified churners)
ROC-AUC Score: 0.86 indicating strong discriminative ability
Business Recommendations
Immediate Actions
- Product Cross-Selling: Incentivize single-product customers to adopt a second product through bundled offerings
- Zero-Balance Monitoring: Implement automated alerts for accounts approaching zero balance
- Regional Strategy: Investigate and address specific pain points in German market
- Age-Targeted Retention: Design age-specific retention programs for high-risk segments
Long-Term Strategy
- Predictive Scoring: Deploy model to generate monthly churn risk scores
- Intervention Campaigns: Allocate retention budget based on predicted churn probability
- A/B Testing: Validate intervention effectiveness on model-identified high-risk customers
- Continuous Learning: Retrain model quarterly with new data to maintain accuracy
Technologies Used
Data Processing: Pandas, NumPy
Machine Learning: Scikit-learn, Imbalanced-learn (SMOTE)
Visualization: Matplotlib, Seaborn
Model Selection: GridSearchCV with 5-fold cross-validation
Results Summary
The Random Forest classifier achieves 85% accuracy in predicting customer churn, with balanced precision-recall tradeoff suitable for business deployment. Feature analysis reveals actionable insights:
- Product engagement is the most controllable predictor
- Geographic disparities require localized strategies
- Zero-balance accounts need proactive engagement
- Age-based segmentation enables targeted interventions
Expected Impact: Implementing model-driven retention strategies could reduce churn by 30-40%, translating to significant revenue protection and improved customer lifetime value.
Dataset
Source: Banking Customer Churn Dataset
Records: 10,000 customers
Period: Cross-sectional snapshot
Geography: France, Germany, Spain
Author: Shree Koshti
Contact: Email | LinkedIn | GitHub
This project demonstrates the application of machine learning to solve real-world business problems in the banking sector, providing actionable insights for customer retention strategy.