SYDsCorner/Movies-ETL
Perform ETL (Extract, Transform, Load) on several movie datasets to predict popular films for a streaming service.
Movies-ETL
Challenge Overview
Purpose:
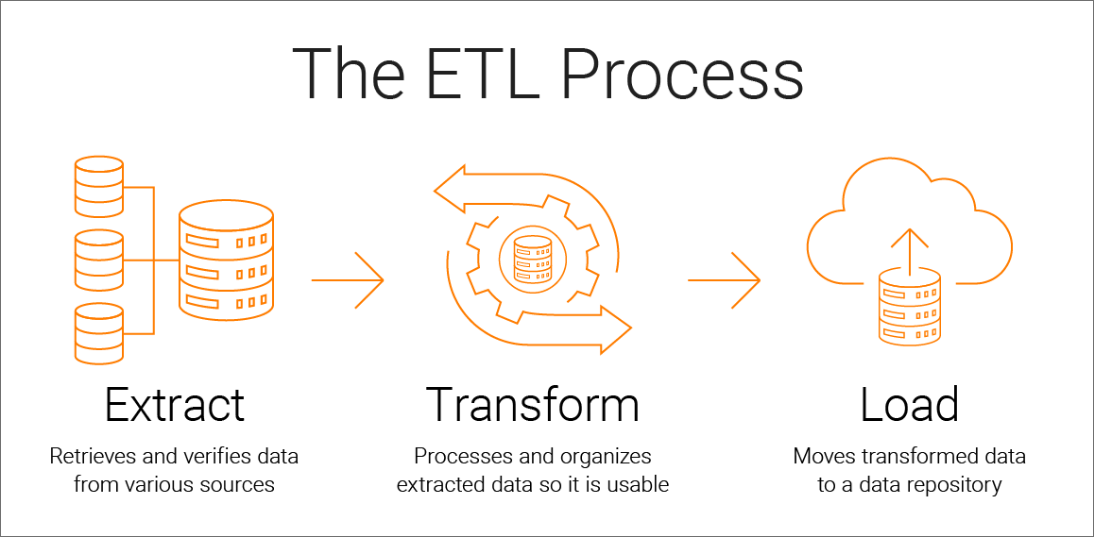
The purpose of this analysis is to use the Extract, Transform, Load (ETL) process to create data pipelines that takes in new data, performs the appropriate transformations, and loads the cleaned dataset into a SQL database.
Resources:
- Software:
- Jupyter Notebooks 6.4.3
- Python 3.8.8
- pgAdmin 4
- Jupyter Notebooks 6.4.3
- Data sources:
The ETL Process (Extract, Transform, Load)
1. Extract: Gathering data from one or multiple sources
- the Wikipedia Movies data stored as a JSON
Movies on Wikipedia from 1990 to 2018
- the Kaggle Data stored in CSVs
The Kaggle dataset pulls from MovieLens website run by the GroupLens research group at the University of Minnesota which is the dataset of over 20 million reviews that contains a metadata file with details about the movies from
the Movie Database (TMDb) and also contains ratings data file which will use for this challenges.
2. Transform: the transformation step is used to clean up your data
-
Create a Function to Clean the Data: that takes in the argument "movie"
-
Create another function that takes in three arguments: Wikipedia data, Kaggle metadata, and MovieLens rating data
-
Read in the three data files
-
Filter out TV shows
-
Iterate through the clean_movie function
-
Use 'try-except' block to catch errors and drop any 'imdb_id' duplicate rows
-
Clean Individual Datasets
- Clean the Wikipedia Movies data
- Parse the Box Office Data
- Parse Budget Data
- Parse Release Date
- Parse Running Time
- Clean the Kaggle Data
- Keep rows where the adult column is False
- Convert Data Types
- Clean the Ratings Data
- Convert the timestamp to a datetime data type
- Clean the Wikipedia Movies data
-
-
Merge Datasets
- Merge the Wikipedia and the Kaggle Metadata into the movies DataFrame
- Drop unnecessary columns
- Fill in the missing data
- Filter and Rename the movies DataFrame for specific columns
- Transform and Merge Rating Data
- Merge the Wikipedia and the Kaggle Metadata into the movies DataFrame
3. Load: Load tranformed data into its final destination
- Connect Pandas and SQL: using Pandas to_sql method paired with sqlAlchemy
- Add the 'movies_df' DataFrame to a SQL database
- Add MovieLens rating CSV data to a SQL database