Rocky111245/Flux-A-Custom-Educational-Deep-Learning-Framework
This neural network framework, built entirely from scratch in C++, offers a robust educational platform for deep learning. It features a custom matrix library and a handcrafted mathematical gradient computation engine, designed to teach neural networks from first principles. I am the sole developer and contributor to this project.
FLUX: A Deep Learning Framework in C++ Built from First Principles
An educational PyTorch/TensorFlow clone with zero external dependencies—pure C++ exposing the mathematics behind neural networks
Table of Contents
- What is FLUX?
- Why Build This?
- Project Status
- The Tensor Library: Core Foundation
- Multi-Layer Perceptron Architecture
- Transformer Components
- Convolutional Neural Networks
- Manual Backpropagation: The Heart of Understanding
- Building and Running
- Project Structure
- Technical Philosophy
What is FLUX?
FLUX is an educational deep learning framework that reimplements the core functionality of PyTorch and TensorFlow from scratch, using only C++ and the Standard Template Library. No external dependencies, no black boxes—just pure C++ implementing every matrix multiplication, every gradient calculation, and every optimization step manually.
It's an educational and performant exercise in understanding neural networks by building them from the ground up. Every architectural decision, every memory layout, every backward pass is implemented explicitly to expose the mathematics and engineering that modern ML frameworks abstract away.
The framework is built around a custom 3D tensor library (also built from first principles) that serves as the computational foundation for all model architectures—Multi-Layer Perceptrons, Convolutional Neural Networks, and Transformers. The tensor library handles all forward and backward operations with explicit gradient tracking, allowing any model configuration to be constructed and trained.
Key Characteristics:
- Pure C++: Only STL, no external libraries (BLAS, cuDNN, Python bindings, etc.)
- Zero Abstraction: Every matrix multiplication, gradient calculation, and weight update is visible and traceable
- Educational Focus: Built to understand neural networks deeply, not for production deployment
- RAII Principles: Smart pointer-based memory management, no manual memory handling
- Any Architecture: Tensor-based foundation supports MLPs, CNNs, and Transformers with unified operations
FLUX provides high-level APIs for easy model construction while maintaining complete transparency. You can build models quickly but every internal operation—forward pass, gradient computation, weight update—is implemented explicitly in readable C++ code.
Modularity and Architectural Flexibility
FLUX layers are fully modular, self-contained objects. Each Neural layer encapsulates its own weights, biases, activations, and gradients—meaning layers can be copied, moved, and reused freely, even after training.
This enables powerful architectural patterns:
Weight Transfer: Copy trained layers between networks for transfer learning or feature extraction:
Neural pretrained_layer(128, Activation_Type::RELU);
// ... train pretrained_layer on task A ...
// Reuse in a new network for task B
Neural new_layer = pretrained_layer; // Copy constructor preserves trained weightsWeight Sharing: Multiple network paths can share the same layer instance (Siamese networks, autoencoders):
Neural shared_encoder(64, Activation_Type::TANH);
NeuralBlock network1({shared_encoder, output_layer1});
NeuralBlock network2({shared_encoder, output_layer2});
// Both networks use identical encoder weightsExample of a MLP (Feed-Forward Network) :
#include <iostream>
#include <iomanip>
#include "tensor-library/TensorLibrary.h"
#include "NeuralBlock.h"
#include "NeuralLayer.h"
int main() {
try {
// ============================================================
// Example: Learn 4-bit parity using a simple feedforward network (MLP)
// ============================================================
// ------------------------------------------------------------
// Data configuration
// ------------------------------------------------------------
constexpr int samples = 16; // total combinations for 4 binary inputs (2^4)
constexpr int features = 4; // number of input bits
constexpr int batch = 1; // single batch for demonstration
Tensor X(samples, features, batch); // input tensor
Tensor Y(samples, 1, batch); // label tensor (target parity)
// ------------------------------------------------------------
// Generate sample input data and expected parity outputs
// ------------------------------------------------------------
// Each sample represents a unique 4-bit binary input.
// The output is 1 if the number of 1-bits is odd, otherwise 0.
int row = 0;
for (int b3 = 0; b3 <= 1; ++b3)
for (int b2 = 0; b2 <= 1; ++b2)
for (int b1 = 0; b1 <= 1; ++b1)
for (int b0 = 0; b0 <= 1; ++b0) {
// Input feature assignment
X(row, 0, 0) = static_cast<float>(b0);
X(row, 1, 0) = static_cast<float>(b1);
X(row, 2, 0) = static_cast<float>(b2);
X(row, 3, 0) = static_cast<float>(b3);
// Label assignment based on parity
int ones = b0 + b1 + b2 + b3;
Y(row, 0, 0) = (ones % 2 == 1) ? 1.0f : 0.0f;
++row;
}
// ------------------------------------------------------------
// Hyperparameters
// ------------------------------------------------------------
constexpr float learning_rate = 0.05f;
constexpr int iterations = 5000;
// ------------------------------------------------------------
// Network definition
// ------------------------------------------------------------
// A minimal three-layer perceptron with non-linear activations.
Neural layer1(4, Activation_Type::GELU);
Neural layer2(8, Activation_Type::GELU);
Neural layer3(1, Activation_Type::SIGMOID);
// Loss function: Binary cross-entropy
Tensor_Loss_Function loss(tensor_loss_function::CROSS_ENTROPY_LOSS, 1);
// ------------------------------------------------------------
// Network assembly
// ------------------------------------------------------------
// The NeuralBlock connects the layers and loss function together.
NeuralBlock block(
X,
{ layer1, layer2, layer3 },
{ loss }
);
// ------------------------------------------------------------
// Training phase
// ------------------------------------------------------------
// The block is trained using a fixed input–output pair.
// Loss is printed periodically for monitoring.
const float avg_loss = block.Train(X, Y, learning_rate, iterations, 250);
std::cout << "\nAverage loss over " << iterations << " iterations: "
<< avg_loss << "\n\n";
// ------------------------------------------------------------
// Evaluation phase
// ------------------------------------------------------------
// Forward pass on the entire dataset to compute predictions.
block.Get_Input_Mutable() = X;
block.Forward_Pass();
const Tensor& predictions = block.Get_Output_View();
int correct = 0;
std::cout << std::fixed << std::setprecision(4);
// Display predictions for each 4-bit input
for (int i = 0; i < samples; ++i) {
int true_label = (Y(i, 0, 0) >= 0.5f) ? 1 : 0;
float prob = predictions(i, 0, 0);
int predicted_label = (prob >= 0.5f) ? 1 : 0;
correct += (predicted_label == true_label);
// Display bits in the natural left-to-right order (b3 b2 b1 b0)
int b0 = static_cast<int>(X(i, 0, 0));
int b1 = static_cast<int>(X(i, 1, 0));
int b2 = static_cast<int>(X(i, 2, 0));
int b3 = static_cast<int>(X(i, 3, 0));
std::cout << "x=" << b3 << b2 << b1 << b0
<< " y=" << true_label
<< " p=" << prob
<< " pred=" << predicted_label << "\n";
}
// ------------------------------------------------------------
// Accuracy summary
// ------------------------------------------------------------
std::cout << "\nAccuracy: " << correct << "/" << samples
<< " (" << (100.0 * correct / samples) << "%)\n";
} catch (const std::runtime_error& e) {
std::cerr << "[Runtime Error] " << e.what() << "\n";
} catch (...) {
std::cerr << "[Unknown Error] Something went wrong.\n";
}
return 0;
}Why Build This?
Modern deep learning frameworks make it trivially easy to build and train neural networks. We can define a model in a few lines of PyTorch and start training immediately. But this convenience comes at a cost: we never see how backpropagation actually works, how gradients flow through layers, or how memory is managed during training.
FLUX exists to expose what frameworks abstract away:
-
See the Mathematics: The equation
∂C/∂w = (∂C/∂a) × h(a) × (∂h/∂a)isn't abstract notation—it's actual code you can read, modify, and debug. Every gradient flows through explicit tensor operations. -
Understand Memory: How are tensors stored? When does allocation happen? How does batching work? These questions have concrete answers in the codebase, not hidden behind framework abstractions.
-
Trace Everything: Open source doesn't just mean you can read the code—it means the code is designed to be read. FLUX architectures (MLPs, CNNs, Transformers) are transparent by design. Follow a gradient from loss back to the first layer.
-
Build Intuition: Implementing backpropagation by hand helped me understand the chain rule at a foundational level. Writing convolution operations reveals why CNNs extract spatial features. Coding attention mechanisms makes Transformers more intuitive.
This framework helps people understand neural network internals deeply, not just use them as black boxes. It's a learning tool for anyone who wants to see beyond the API.
Project Status
FLUX is a work in progress, developed alongside my research Master's in Computer Science. This is an ambitious, long-term educational project.
✅ Multi-Layer Perceptron (Complete & Tested)
- Status: Fully functional, production-ready for educational use
- Validation: Successfully trained on 4-bit parity problem
- Testing: Multi-layer networks converge correctly
- Features: Forward/backward propagation, multiple activation functions, gradient descent optimization, batch processing
🔄 Transformers (Core Components Implemented)
- Complete: BPE tokenizer, token embeddings, positional encoding, single/multi-head attention, layer normalization, residual connections
- In Progress: Full Transformer glue code, training loops, backpropagation, sequence generation
- Note: FLUX is very modular. The MLP block can be used and attached to the transformer block without rewriting code.
🔄 Convolutional Neural Networks (Core Components Implemented)
- Complete: Convolutional layers, pooling (max/average), padding strategies (VALID/SAME), im2row (specialized algorithm from im2col) algorithm, kernel operations
- In Progress: Backpropagation through conv/pooling layers
- Note: Gradient computation under development
The Tensor Library: Core Foundation
The Tensor class is FLUX's computational engine. FLUX implements tensor operations from scratch with full visibility.
Memory Layout and Implementation
class Tensor {
public:
Tensor(int rows, int columns, int depth);
// Element access: row-major ordering
float& operator()(int row, int column, int depth) noexcept;
// Dimensions
int rows() const noexcept;
int columns() const noexcept;
int depth() const noexcept;
private:
int rows_ = 0;
int columns_ = 0;
int depth_ = 0;
std::unique_ptr<float[]> data_; // Contiguous memory, RAII managed
// Index computation: depth is slowest dimension
int Index(int row, int column, int depth_idx) const noexcept {
return depth_idx * rows_ * columns_ + row * columns_ + column;
}
};Key Design Decisions:
Contiguous Memory: All tensor data stored in a single std::unique_ptr<float[]> allocation. No nested arrays, no fragmentation—one contiguous block for cache efficiency.
Row-Major Ordering: Index computation is depth × (rows × cols) + row × cols + col. This means:
- Row is the fastest-changing dimension (best cache locality for matrix operations)
- Column is the second-fastest
- Depth is the slowest (each depth slice is a complete matrix)
3D Structure: A tensor with depth 3 is literally three matrices stacked in 3D space. For example, Tensor(28, 28, 3) represents a 28×28 RGB image with three color channels arranged sequentially in memory.
Smart Pointer Management: Using std::unique_ptr ensures automatic cleanup, no memory leaks, and clear ownership semantics. All memory management follows strict RAII principles—no manual new/delete anywhere.
Core Tensor Operations
// Element-wise operations
void Tensor_Add_Tensor_ElementWise(Tensor& result, const Tensor& a, const Tensor& b);
void Tensor_Multiply_Tensor_ElementWise(Tensor& result, const Tensor& a, const Tensor& b);
void Tensor_Multiply_Scalar_ElementWise(Tensor& result, const Tensor& a, float scalar);
// Matrix multiplication (batched)
void Tensor_Multiply_Tensor(Tensor& result, const Tensor& a, const Tensor& b);
// Tensor manipulation
void Tensor_Transpose(Tensor& result, const Tensor& input);
void Tensor_Broadcast_At_Depth(Tensor& result, const Tensor& input, int target_depth);
// Initialization
void Tensor_Xavier_Uniform_MLP(int fan_in, int fan_out);
void Tensor_Xavier_Uniform_Conv(int number_of_kernels);These operations power all architectures. The same Tensor_Multiply_Tensor function handles every computation for the MLP,CNN,Transformers:
Unified API, Different Interpretations: The depth dimension means different things in different contexts (batch size, channels, attention heads), but the underlying operations remain consistent.
Project Structure
FLUX/
├── model-architectures/
│ ├── multi-layer-perceptron/
│ │ ├── mlp-feed-forward/
│ │ │ ├── NeuralLayer.cpp # Single layer
│ │ │ └── NeuralBlock.cpp # Network container
│ │ └── main.cpp # Working examples
│ ├── transformers/
│ │ ├── tokenizer/ # BPE implementation
│ │ ├── token_embedding/ # Embedding layers
│ │ ├── positional-embeddings/ # Position encoding
│ │ ├── single-attention-head/ # Attention mechanism
│ │ ├── multi-head-attention/ # Multi-head wrapper
│ │ ├── layer-normalization/ # Layer norm
│ │ └── residual-stream/ # Skip connections
│ └── convolutional-neural-networks/
│ ├── convolutional-layer/ # Conv2D ops
│ ├── pooling-layer/ # Pooling ops
│ ├── kernels/ # Kernel management
│ └── padding-functions/ # VALID/SAME padding
│
├── tensor-library/
│ ├── TensorLibrary.h # Main computational engine
│ └── TensorLibrary.cpp
│
├── matrix-library/ # Legacy 2D utility
│ ├── MatrixLibrary.h
│ └── MatrixLibrary.cpp
│
├── activation-functions/ # ReLU, Sigmoid, Tanh, etc.
├── activation-function-derivatives/ # Gradient computations
├── loss-functions/ # MSE, Cross-entropy
└── web-visualizations/ # Training monitoring
Organization Principle: Each model architecture has its own directory with components organized by functionality. Shared computational libraries (tensors, activations) live at the root level.
Multi-Layer Perceptron Architecture
The MLP implementation is complete and battle-tested. It demonstrates FLUX's layered architecture: Neural Layers organized into Neural Blocks.

Architecture Components
Neural Layer: A single fully-connected layer with its own weights, biases, activation function, and gradient tensors. Each Neural object is self-contained—it knows how to forward propagate and backpropagate within itself.
Neural Block: A container managing multiple layers as a complete network. The Neural_Block class handles:
- Sequential layer connections (output of layer N feeds into layer N+1)
- Training loop (forward pass → loss → backward pass → weight updates)
- Inference (forward pass only)
Building an MLP
From model-architectures/multi-layer-perceptron/main.cpp:
#include <iostream>
#include <iomanip>
#include "tensor-library/TensorLibrary.h"
#include "NeuralBlock.h"
#include "NeuralLayer.h"
int main() {
try {
// ============================================================
// Example: Learn 4-bit parity using a simple feedforward network (MLP)
// ============================================================
// ------------------------------------------------------------
// Data configuration
// ------------------------------------------------------------
constexpr int samples = 16; // total combinations for 4 binary inputs (2^4)
constexpr int features = 4; // number of input bits
constexpr int batch = 1; // single batch for demonstration
Tensor X(samples, features, batch); // input tensor
Tensor Y(samples, 1, batch); // label tensor (target parity)
// ------------------------------------------------------------
// Generate sample input data and expected parity outputs
// ------------------------------------------------------------
// Each sample represents a unique 4-bit binary input.
// The output is 1 if the number of 1-bits is odd, otherwise 0.
int row = 0;
for (int b3 = 0; b3 <= 1; ++b3)
for (int b2 = 0; b2 <= 1; ++b2)
for (int b1 = 0; b1 <= 1; ++b1)
for (int b0 = 0; b0 <= 1; ++b0) {
// Input feature assignment
X(row, 0, 0) = static_cast<float>(b0);
X(row, 1, 0) = static_cast<float>(b1);
X(row, 2, 0) = static_cast<float>(b2);
X(row, 3, 0) = static_cast<float>(b3);
// Label assignment based on parity
int ones = b0 + b1 + b2 + b3;
Y(row, 0, 0) = (ones % 2 == 1) ? 1.0f : 0.0f;
++row;
}
// ------------------------------------------------------------
// Hyperparameters
// ------------------------------------------------------------
constexpr float learning_rate = 0.05f;
constexpr int iterations = 5000;
// ------------------------------------------------------------
// Network definition
// ------------------------------------------------------------
// A minimal three-layer perceptron with non-linear activations.
Neural layer1(4, Activation_Type::GELU);
Neural layer2(8, Activation_Type::GELU);
Neural layer3(1, Activation_Type::SIGMOID);
// Loss function: Binary cross-entropy
Tensor_Loss_Function loss(tensor_loss_function::CROSS_ENTROPY_LOSS, 1);
// ------------------------------------------------------------
// Network assembly
// ------------------------------------------------------------
// The NeuralBlock connects the layers and loss function together.
NeuralBlock block(
X,
{ layer1, layer2, layer3 },
{ loss }
);
// ------------------------------------------------------------
// Training phase
// ------------------------------------------------------------
// The block is trained using a fixed input–output pair.
// Loss is printed periodically for monitoring.
const float avg_loss = block.Train(X, Y, learning_rate, iterations, 250);
std::cout << "\nAverage loss over " << iterations << " iterations: "
<< avg_loss << "\n\n";
// ------------------------------------------------------------
// Evaluation phase
// ------------------------------------------------------------
// Forward pass on the entire dataset to compute predictions.
block.Get_Input_Mutable() = X;
block.Forward_Pass();
const Tensor& predictions = block.Get_Output_View();
int correct = 0;
std::cout << std::fixed << std::setprecision(4);
// Display predictions for each 4-bit input
for (int i = 0; i < samples; ++i) {
int true_label = (Y(i, 0, 0) >= 0.5f) ? 1 : 0;
float prob = predictions(i, 0, 0);
int predicted_label = (prob >= 0.5f) ? 1 : 0;
correct += (predicted_label == true_label);
// Display bits in the natural left-to-right order (b3 b2 b1 b0)
int b0 = static_cast<int>(X(i, 0, 0));
int b1 = static_cast<int>(X(i, 1, 0));
int b2 = static_cast<int>(X(i, 2, 0));
int b3 = static_cast<int>(X(i, 3, 0));
std::cout << "x=" << b3 << b2 << b1 << b0
<< " y=" << true_label
<< " p=" << prob
<< " pred=" << predicted_label << "\n";
}
// ------------------------------------------------------------
// Accuracy summary
// ------------------------------------------------------------
std::cout << "\nAccuracy: " << correct << "/" << samples
<< " (" << (100.0 * correct / samples) << "%)\n";
} catch (const std::runtime_error& e) {
std::cerr << "[Runtime Error] " << e.what() << "\n";
} catch (...) {
std::cerr << "[Unknown Error] Something went wrong.\n";
}
return 0;
}Layer Connections: Each layer stores the previous layer's output as its input. Gradients flow backward through these connections during backpropagation.
Validation: 4-Bit Parity Problem
The 4-bit parity problem tests whether a network can learn non-linear patterns (XOR-like logic). FLUX successfully trains to 100% accuracy (overfit):

This validates:
- ✅ Gradient flow through multiple layers
- ✅ Activation function derivatives computed correctly
- ✅ Weight updates converge to optimal solution
- ✅ Network capacity sufficient for non-linear decision boundaries
Video Demo (New Version)
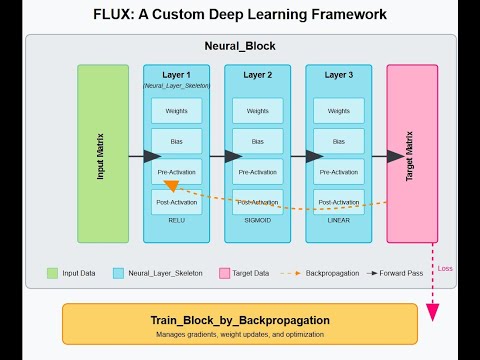
Video Demo (Older Version-More Descriptive)
Note: This video shows an earlier version of FLUX with the same core design patterns (tensor-based architecture, explicit backpropagation). The current implementation is more refined but follows identical principles.
Transformer Components
Transformer architecture components are implemented modularly. Each piece works independently but isn't yet assembled into a complete Transformer block.
Implemented Components
Byte-Pair Encoding Tokenizer
- Full BPE algorithm with vocabulary building
- Text encoding to token IDs
- Optimized for reasonable corpus sizes
Token & Positional Embeddings
- Learnable embedding matrix
[vocab_size × d_model] - Fixed sinusoidal positional encoding
- Embedding arithmetic operations
Attention Mechanisms
- Single attention head with scaled dot-product attention
- Multi-head attention (splitting, parallel computation, concatenation)
- Query, Key, Value transformations
Normalization & Residuals
- Layer normalization with learnable parameters
- Residual stream connections for skip pathways
Note: Core components implemented, backpropagation remaining. See model-architectures/transformers/ for implementation details.
Convolutional Neural Networks
CNN infrastructure has most core implemented (kernels,padding,im2rows algorithm).
Implemented Features
Convolutional Layers
- Arbitrary kernel sizes and counts
- Stride and padding configuration
- Multiple activation functions
- Xavier initialization for kernels
Pooling Operations
- Max pooling (with index tracking for backprop)
- Average pooling
- Configurable window sizes and strides
Padding Strategies
- VALID (no padding): Output size reduces
- SAME (zero padding): Output size maintained (stride=1)
Im2Rows Algorithm
- A variation of the famous im2col algorithm
- Efficient convolution via matrix multiplication
- Transforms image patches to column vectors
- Multiplies with flattened kernels
Note:Core components implemented, backpropagation remaining. See model-architectures/convolutional-neural-networks/ for implementation status.
Manual Backpropagation: The Heart of Understanding
Backpropagation is implemented manually—no automatic differentiation. This is intentional. Understanding gradient flow is the entire point.
However, public APIs are present and can just train a model using model.Train().
Why Manual Implementation?
Autograd Hides Everything: PyTorch's loss.backward() is one line. You never see how gradients flow, never debug the chain rule, never understand why vanishing gradients occur.
Manual Forces Understanding: Writing backpropagation myself meant:
- Deriving each gradient mathematically
- Implementing the chain rule explicitly
- Tracking tensor dimensions carefully
- Debugging numerical stability issues
Educational Value: We can internalize the mathematics by coding it. The equation ∂C/∂w = (∂C/∂a) × h(a) × (∂h/∂a) becomes concrete when we write it as tensor operations.
Backward Pass Implementation
For each neural layer (MLP):
// Backpropagation through fully-connected layer (manual, no autograd)
//
// Forward pass per layer:
// Shapes:
// Input X: [S, I, B] (sequence/samples, input-dim, batch)
// Weights W: [N, I, 1] (output-neurons, input-dim, shared across batch)
// Bias b: [1, N, 1] (shared across batch)
// Pre-activation z: [S, N, B]
// Post-activation a: [S, N, B]
//
// Operations:
// z = X · W^T + b // b broadcast over S and B
// a = f(z)
//
// Backward pass (let δ := dL/dz):
// Given: dL/da ∈ [S, N, B] from next layer
//
// 1) Local delta:
// δ = (dL/da) ⊙ f'(z) // [S, N, B]
//
// 2) Weight gradients:
// dL/dW = Σ_B ( X^T · δ ) // [N, I, 1]
// where X^T · δ : [I, S, B] × [S, N, B] → [I, N, B]
// (matmul sums over sequence S), then Σ over batch B → [I, N],
// then transpose → [N, I, 1]
//
// 3) Bias gradients:
// dL/db = Σ_{B,S} δ // [1, N, 1]
//
// 4) Error to previous layer:
// dL/dX = δ · W // [S, I, B]
//
// Execution order:
// 1) Receive dL/da
// 2) Compute δ = (dL/da) ⊙ f'(z)
// 3) Compute dL/dW via X^T · δ (sums over S), then reduce over B
// 4) Compute dL/db by summing δ over S and B
// 5) Propagate dL/dX = δ · W
void NeuralBlock::BackPropagate(const Tensor& upstream_error_dL_da) {
assert(block_size_>0 && "Block size must be greater than 0 in NeuralBlock::BackPropagate().");
assert(!layers_.empty());
assert(forward_pass_called_ && "BackPropagate() requires Forward_Pass() first");
// Shape checks
{
const auto& top_out = layers_.back().Get_Output_View();
assert(upstream_error_dL_da.rows() == top_out.rows() &&
upstream_error_dL_da.columns() == top_out.columns() &&
upstream_error_dL_da.depth() == top_out.depth() &&
"Upstream gradient must match top layer output [S,N_last,B]");
}
upstream_error_entering_block_ = upstream_error_dL_da;
//We start from the top of the stack (layers of the MLP)
for (size_t i = layers_.size(); i-- > 0; ) {
if (i == layers_.size() - 1) {
layers_[i].Backpropagate(upstream_error_dL_da);
} else {
const Tensor& error_gradient = layers_[i + 1].Get_Downstream_Error(); // [S, I_i, B]
layers_[i].Backpropagate(error_gradient);
}
}
downstream_error_leaving_block_ = layers_.front().Get_Downstream_Error(); // to previous block
back_propagation_done_ = true;
upstream_error_set_= true;
downstream_error_set_ = true;
}Chain Rule in Action: Each step corresponds to one term in the chain rule.No hidden computation—just careful application of calculus translated to tensor operations.
Gradient Descent
Weight updates use vanilla SGD:
// This is after the full network has been backpropagated.
void NeuralBlock::Update_Block(const float learning_rate) {
assert(back_propagation_done_ && "Update_Block() requires BackPropagate() first");
for (auto& layer : layers_) {
layer.Update_Parameters(learning_rate);
}
update_block_called_ = true;
}More sophisticated optimizers (Adam, RMSprop) are planned but not yet implemented. The focus is correctness first, optimization second.
Building and Running
Prerequisites
- CMake 3.26+
- C++23 compiler (GCC 13+, Clang 16+, MSVC 2022+)
- No external libraries (only C++ STL)
Build Instructions
git clone https://github.com/Rocky111245/Flux-A-Custom-Educational-Deep-Learning-Framework.git
cd Flux-A-Custom-Educational-Deep-Learning-Framework
mkdir build && cd build
cmake ..
cmake --build .Available Executables
# Multi-Layer Perceptron examples and tests
./MLP_main
# Transformer component demonstrations
./Transformer_main
# Real-time training visualization server
./WebVis_main
# Main project executable (general demonstrations)
./FluxNeuralNetworkFrameworkCMake Build Targets
Static Libraries:
NeuralCore- Core computational components (tensors, activations, loss functions)MultiLayerPerceptron- MLP-specific architecture and trainingTransformerModel- Transformer components (attention, embeddings, tokenization)WebVisualization- Real-time training monitoring and data serialization
Executables:
MLP_main- MLP examples and validation (4-bit parity, multi-layer tests)Transformer_main- Individual Transformer component testsWebVis_main- WebSocket server for live training visualizationFluxNeuralNetworkFramework- Main project demonstrations
Technical Philosophy
Understanding Through Building
This project embodies a specific philosophy: understanding comes from implementation, not just usage. You can read papers about backpropagation, watch lectures, work through derivations—but until you've implemented it yourself, debugged gradient flow, and fixed numerical instability, you don't truly understand it.
Transparency Over Convenience
FLUX is intentionally low-level and explicit. It doesn't hide memory management, doesn't abstract away gradients, and doesn't use computational graphs. This makes it harder to use than PyTorch, but that difficulty is the learning opportunity.
Modern frameworks optimize for productivity. FLUX optimizes for understanding. Every operation is traceable, every gradient is visible, every architectural decision is explicit in the code.
Open Source, Open Mathematics
FLUX is open source not just in license but in philosophy. The code is designed to be read, not just executed. Variable names are descriptive, operations are explicit, and the mathematics maps directly to the implementation.
When you see ∂L/∂w in a paper, you can find dL_dw_ in the codebase. When you read about attention mechanisms, you can trace through SingleAttentionHead::Forward(). The theory and practice are aligned.
Long-Term Learning Project
This is not a sprint to production. It's a multi-year educational journey undertaken alongside Master's research. Progress happens incrementally, architecture by architecture, with each component understood deeply before moving forward.
The goal is not to replace PyTorch. It's to create a tool for learning—for anyone who wants to understand how neural networks actually work beneath the high-level APIs.
Project Status: Active development alongside Master's research
Last Updated: November 2025
License: Open source for educational purposes